 : Grounding Large Language Models to Holistic Segmentation
: Grounding Large Language Models to Holistic Segmentation
We present GROUNDHOG ,
a multimodal large language model developed by grounding large language models to holistic segmentation.
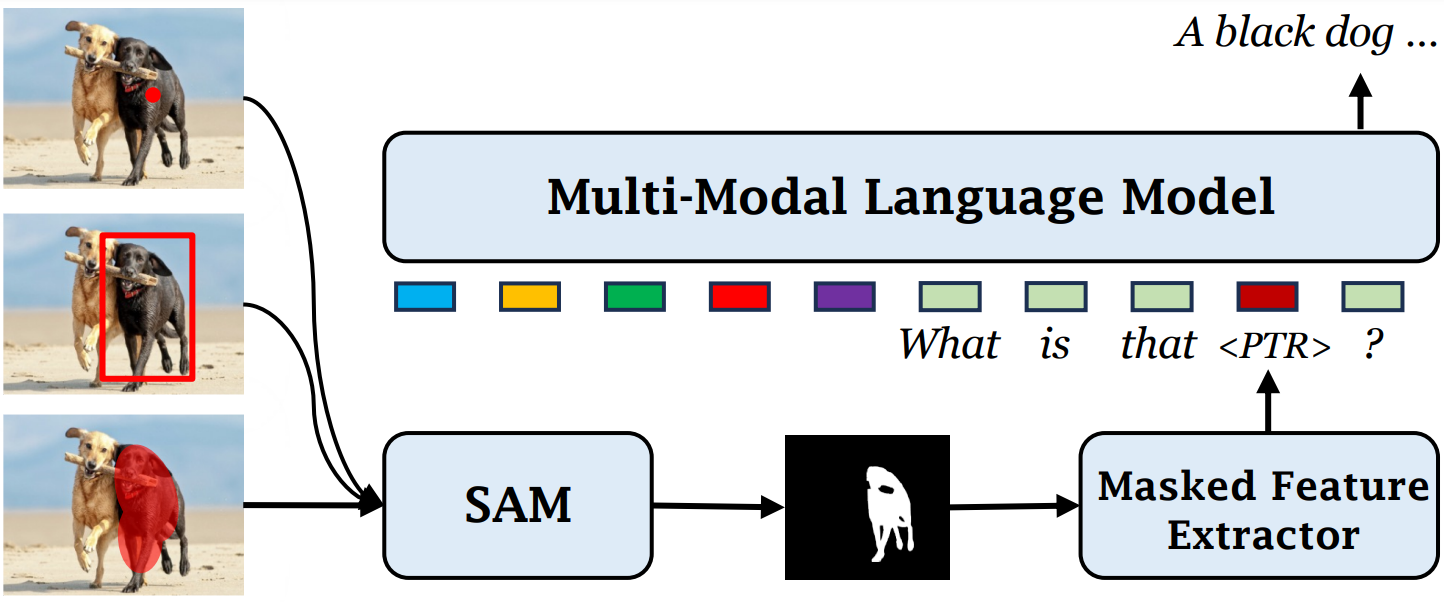
GROUNDHOG is flexible and diagnosable, reduces object hallucination, and can plug in and play with any segmentation foundation model (e.g., SAM).
: Grounding LLMs to Holistic Segmentation
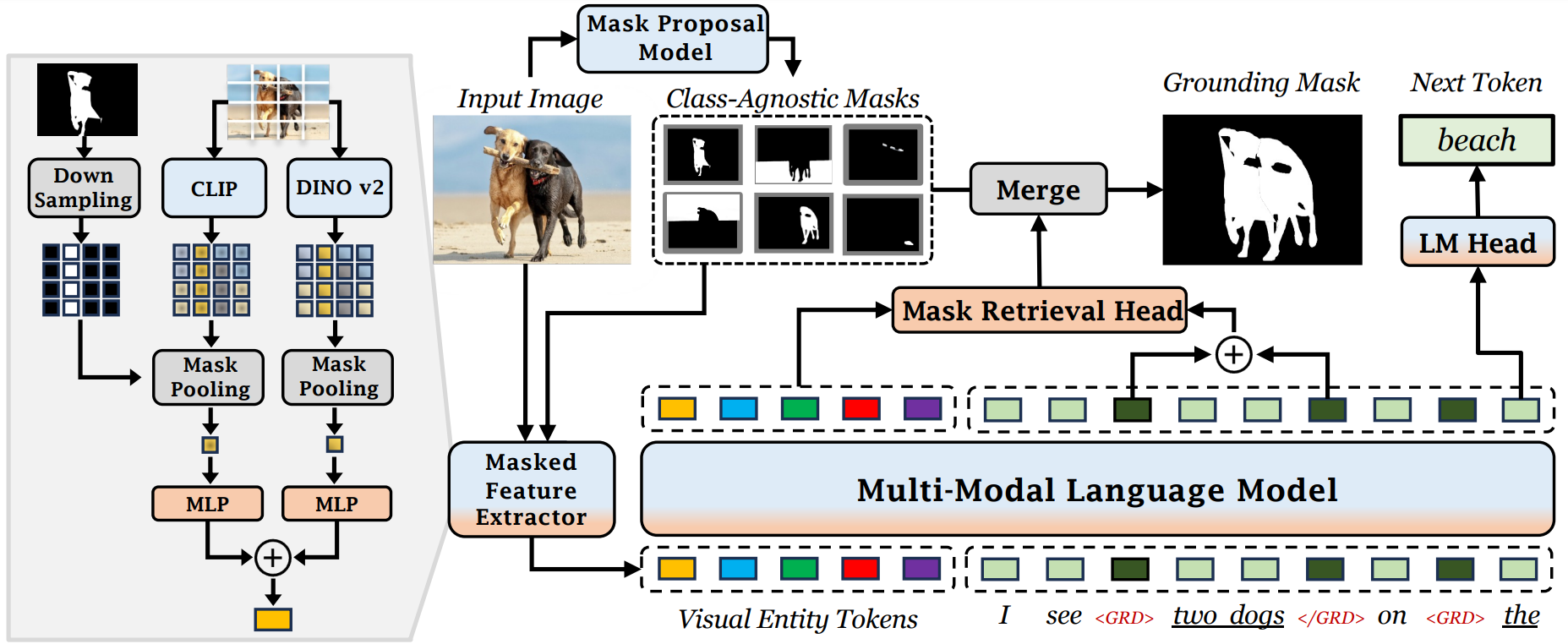
formulate the grounding process as an entity segment selection problem which involves
(1) proposing entity segmentation masks where the masks encapsulate regions with discernible semantic content, and
(2) recognizing the retrieved entities through the understanding of both visual and language context.
incorporates a masked feature extractor that takes an input image and a set of class-agnostic entity mask proposals,
and converts each mask's features into visual entity tokens for an MLLM backbone.
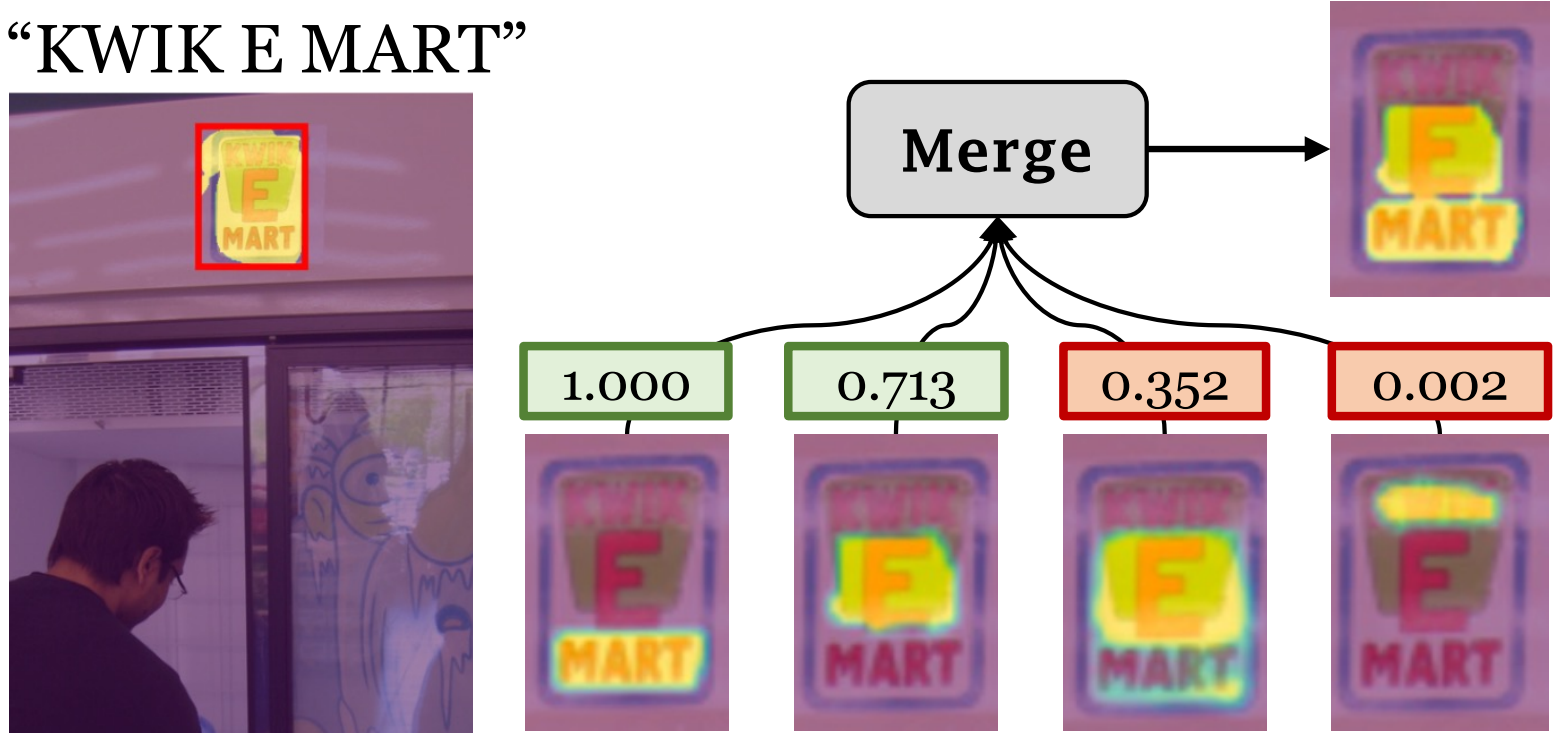
This MLLM then connects groundable phrases to unified grounding masks by retrieving and merging the entity masks.
To enable holistic entity mask proposals, our default mask proposal model is an enhanced Mask2Former
with 50 additional queries each for segmenting parts and text regions, alongside the original 200 entity queries.







@inproceedings{zhang2024groundhog,
title={GROUNDHOG: Grounding Large Language Models to Holistic Segmentation},
author={Zhang, Yichi and Ma, Ziqiao and Gao, Xiaofeng and Shakiah, Suhaila and Gao, Qiaozi and Chai, Joyce},
booktitle={Conference on Computer Vision and Pattern Recognition 2024},
year={2024}
}