 : Grounding Large Language Models to Holistic Segmentation
: Grounding Large Language Models to Holistic Segmentation
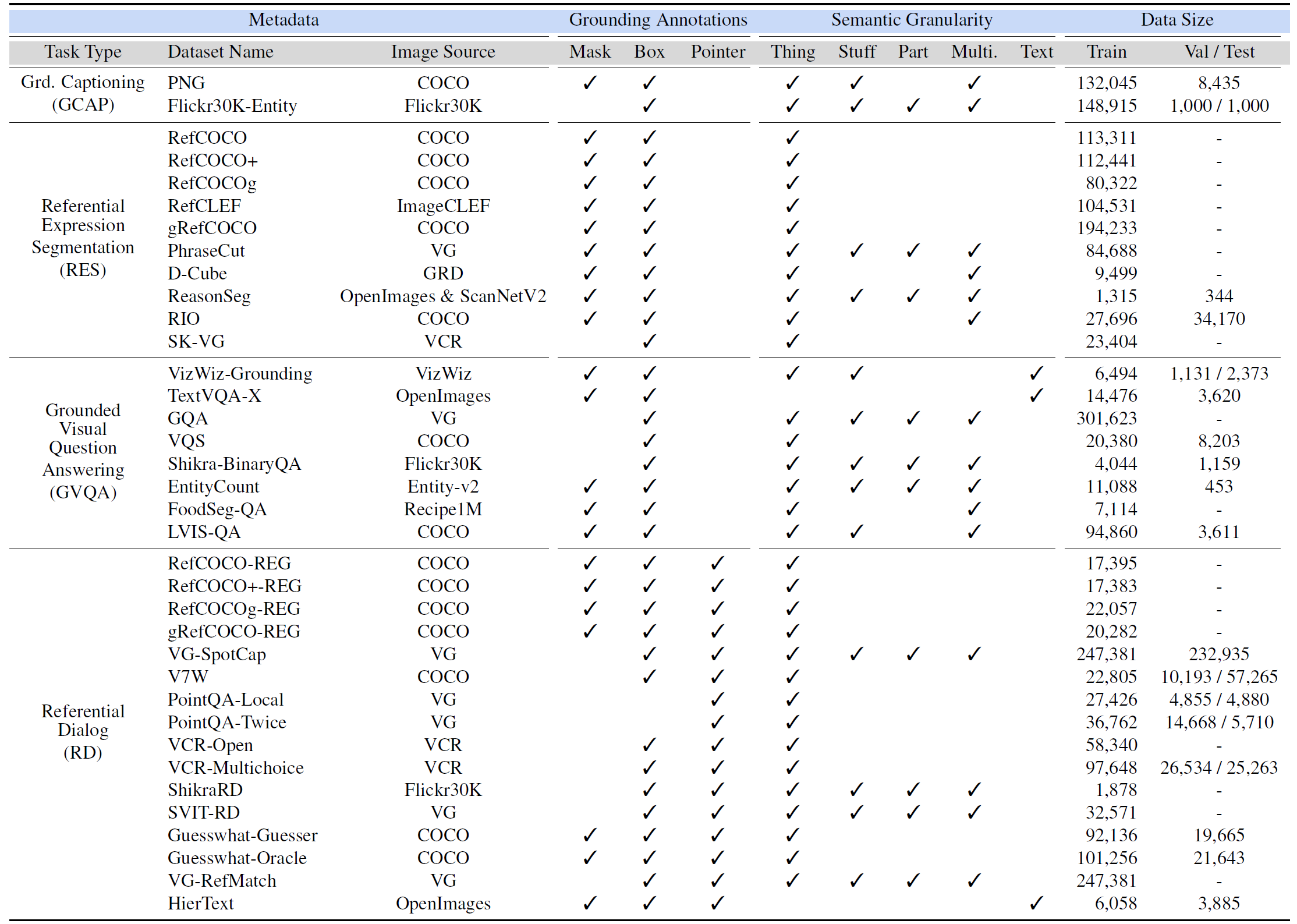
















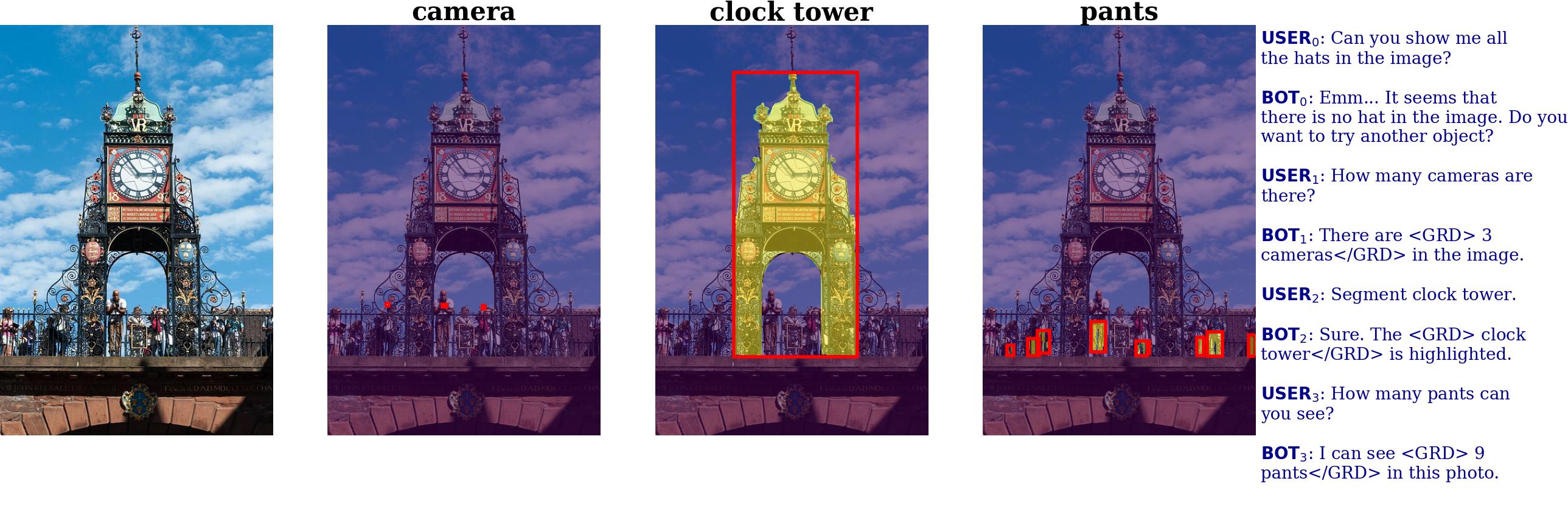

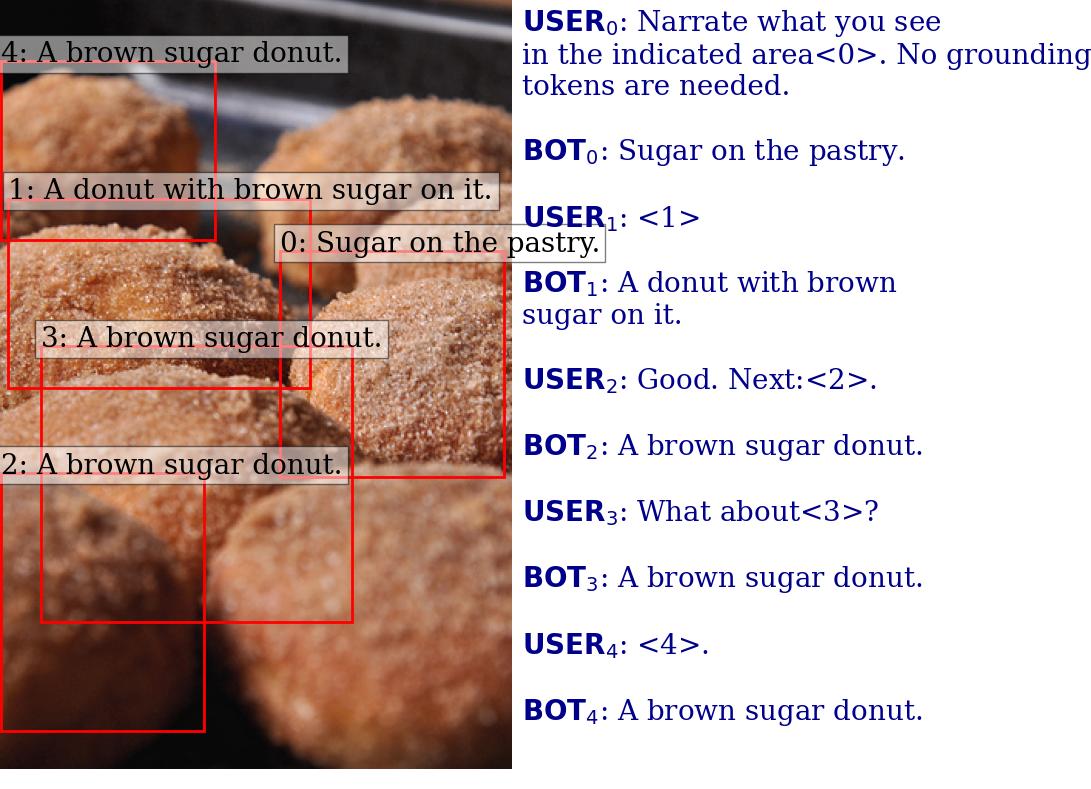









@inproceedings{zhang2024groundhog,
title={GROUNDHOG: Grounding Large Language Models to Holistic Segmentation},
author={Zhang, Yichi and Ma, Ziqiao and Gao, Xiaofeng and Shakiah, Suhaila and Gao, Qiaozi and Chai, Joyce},
booktitle={Conference on Computer Vision and Pattern Recognition 2024},
year={2024}
}